How to make a STOCK price scraper command-line application using Python and Web Scraping
If you like me like to check the stock prices from time to time, but don’t want to navigate around the websites to find the details you are looking for, then this CLI application might be the perfect tool for you. Thanks to Python it’s easy for us to get data from the internet using BeautifulSoup.
Imagine you would like the latest price for Microsoft, then the only command you would need to enter is: python .\stockPrice.py MSFT inside your terminal. In this tutorial, I will teach you how to scrape stock prices from Yahoo Finance in only 24 lines.
Create the python file and install BS4 (BeautifulSoup)
Install BeautifulSoup through PowerShell with PIP
The first thing you have to do is install BS4 using PIP. The command for doing this is pip install bs4 – you should get a result like mine below when doing it:
PS C:\Users\chs\Desktop> pip install bs4
Defaulting to user installation because normal site-packages is not writeable
Collecting bs4
Downloading bs4-0.0.1.tar.gz (1.1 kB)
Collecting beautifulsoup4
Downloading beautifulsoup4-4.10.0-py3-none-any.whl (97 kB)
|████████████████████████████████| 97 kB 1.3 MB/s
Collecting soupsieve>1.2
Downloading soupsieve-2.3-py3-none-any.whl (37 kB)
Using legacy 'setup.py install' for bs4, since package 'wheel' is not installed.
Installing collected packages: soupsieve, beautifulsoup4, bs4
Running setup.py install for bs4 ... done
Successfully installed beautifulsoup4-4.10.0 bs4-0.0.1 soupsieve-2.3Create the python file stockPrice.py
Now we have to make the fun stuff (coding). Go ahead and create a new python file and name it stockPrice or what you prefer and place it somewhere you can remember (location doesn’t matter). First, we need to make our imports including the newly installed bs4 library. The first four lines should contain this code:
import os
import sys
import requests
from bs4 import BeautifulSoupIn order to make the application more dynamic, our user has to enter a ticker (stock identifier). By making use of the sys library, we can check if the user actually entered a value for the ticker. If the user doesn’t enter a ticker, we would like to return an error message and also do it if the user forgets to enter a ticker for the stock.
When the ticker has been entered, we would like to store it in a variable so that we can access the value later when making a web request to Yahoo Finance.
if len(sys.argv) > 2:
print('You are only allowed to enter one ticker at a time. Please try again.')
sys.exit()
if len(sys.argv) < 2:
print('You have to provide a ticker for the stock. Please try again.')
sys.exit()
ticker = sys.argv[1]With the ticker in place, we can now go ahead and make a request for our ticker at Yahoo Finance. The URL request has to be dynamic in order for it to change depending on the user input. 'https://finance.yahoo.com/quote/' + ticker + '?p=' + ticker + '&.tsrc=fin-srch'. This will result in URLs that look like the following:
- Apple – https://finance.yahoo.com/quote/AAPL?p=AAPL&.tsrc=fin-srch
- Microsoft – https://finance.yahoo.com/quote/MSFT?p=MSFT&.tsrc=fin-srch
- Tesla – https://finance.yahoo.com/quote/TSLA?p=TSLA&.tsrc=fin-srch
When making a request, we get a response – let’s store that inside a new variable named stockResponse. This variable is also the one responsible for making the request with our Stock ticker URL. It will look like the following:
stockURL = 'https://finance.yahoo.com/quote/' + ticker + '?p=' + ticker + '&.tsrc=fin-srch'
stockResponse = requests.get(stockURL)So far so good – your stockPrice.py file at the moment, should look like the one below:
import os
import sys
import requests
from bs4 import BeautifulSoup
if len(sys.argv) > 2:
print('You are only allowed to enter one ticker at a time. Please try again.')
sys.exit()
if len(sys.argv) < 2:
print('You have to provide a ticker for the stock. Please try again.')
sys.exit()
ticker = sys.argv[1]
stockURL = 'https://finance.yahoo.com/quote/' + ticker + '?p=' + ticker + '&.tsrc=fin-srch'
stockResponse = requests.get(stockURL)Python Web Scraping Stock Price
For this tutorial, I will be scraping the MSFT ticker. How do we know where the stock price is inside the returned response? For that, we need to make a visit to the stock page at Yahoo Finance. Mark the stock price on the webpage, right-click it, and select inspect.
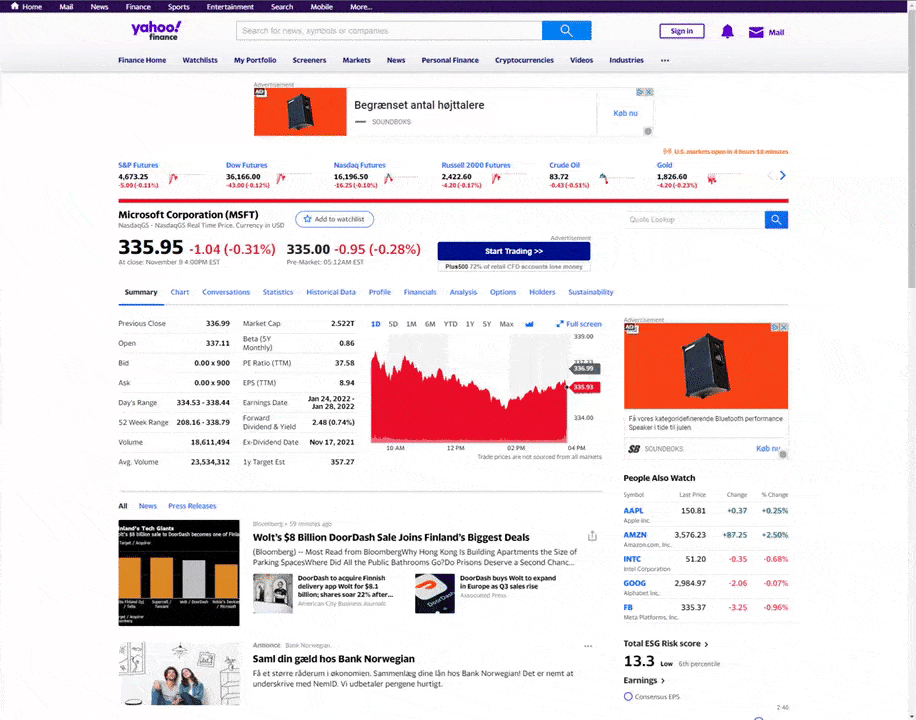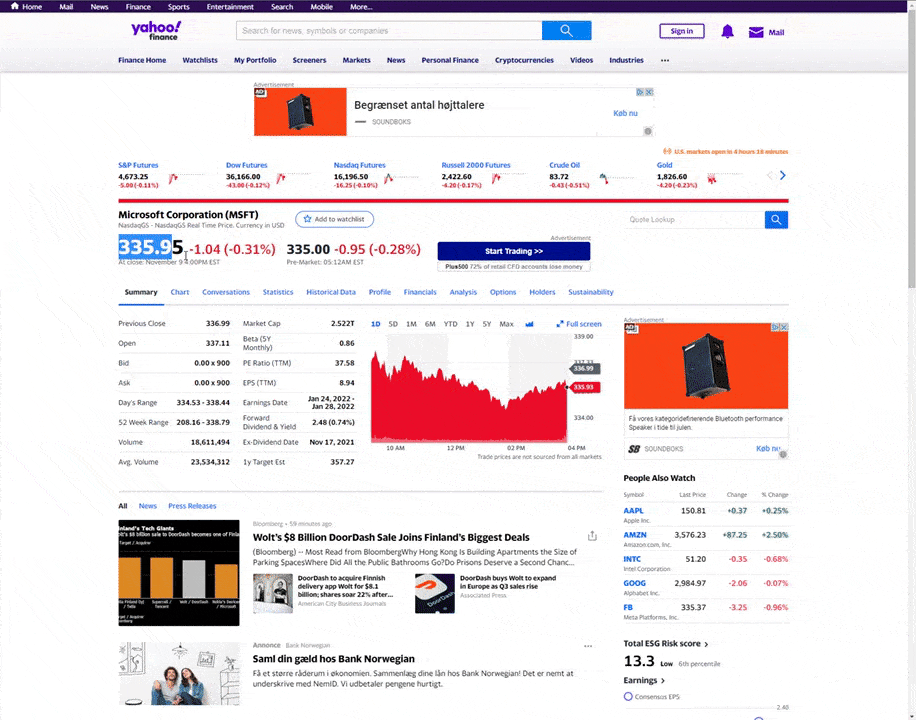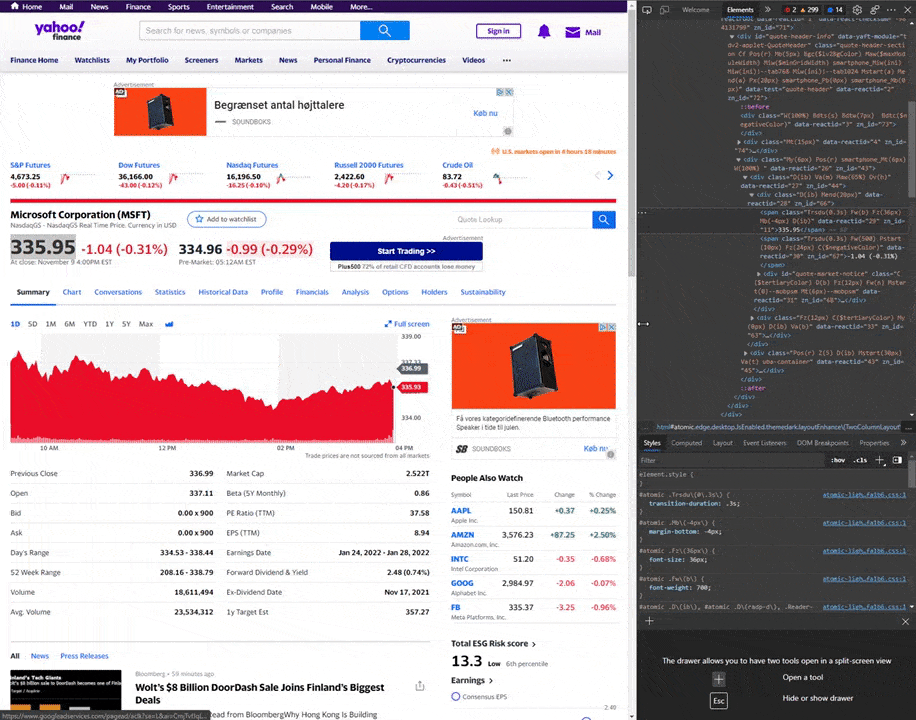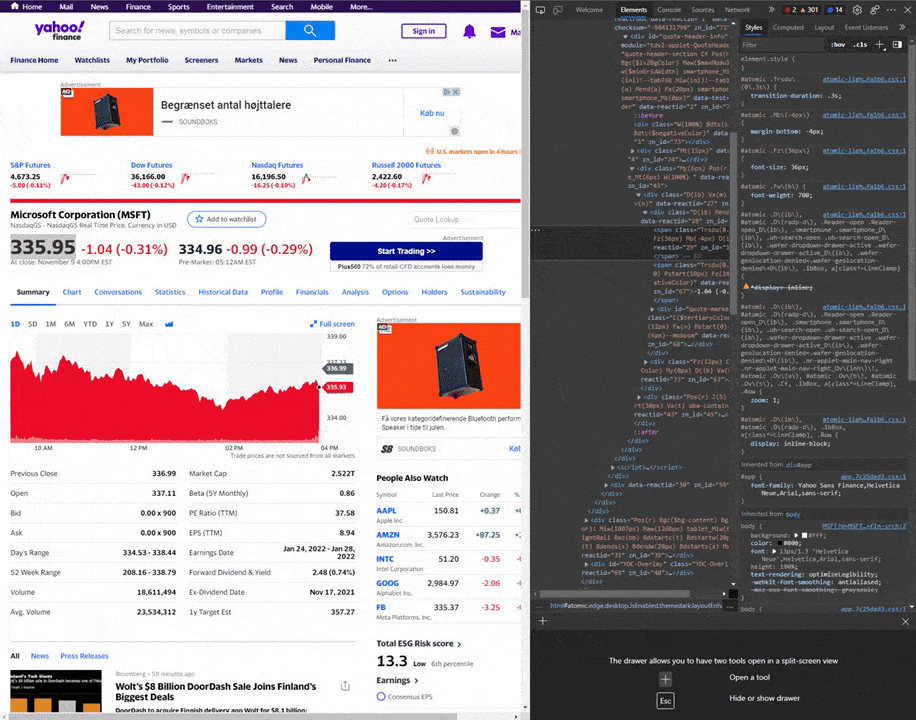
So now we got a large popup on the right (or in some cases bottom) of our screen. This is the webpage’s DOM. Here the browser has selected the stock price element on the website for us.
Now you have to select and copy the content inside the quotes of the class for the element.
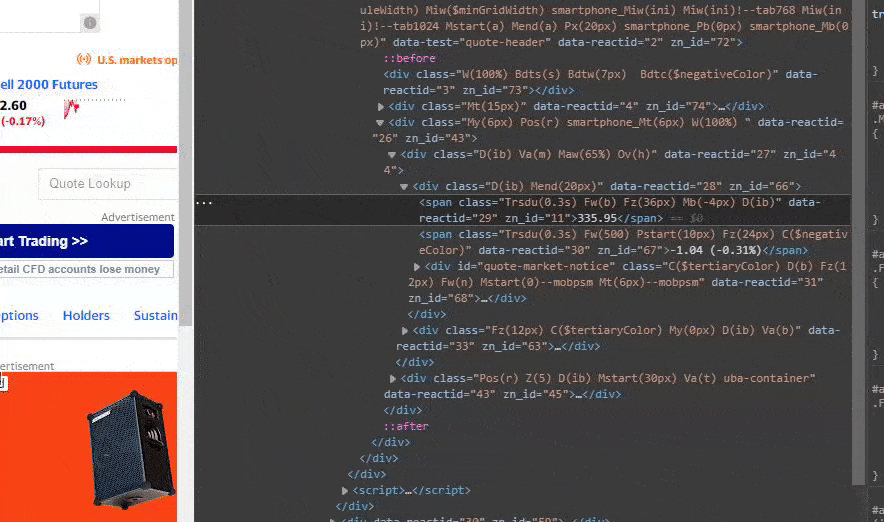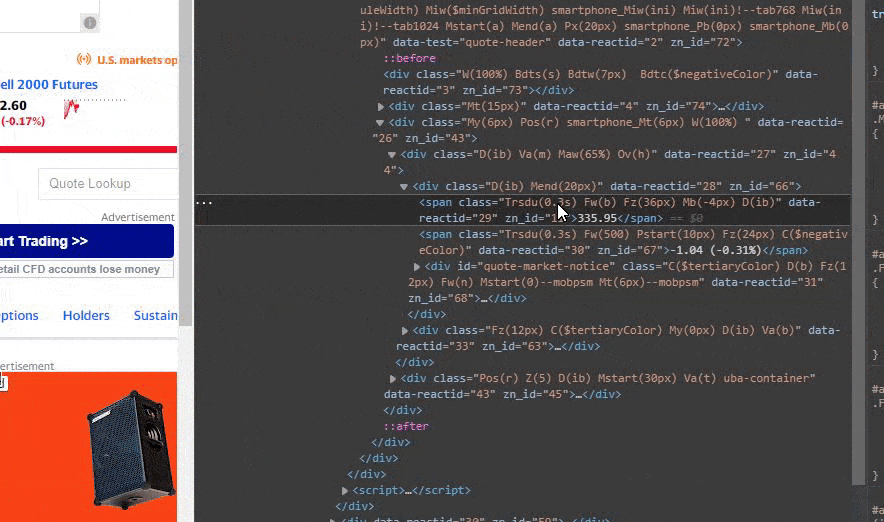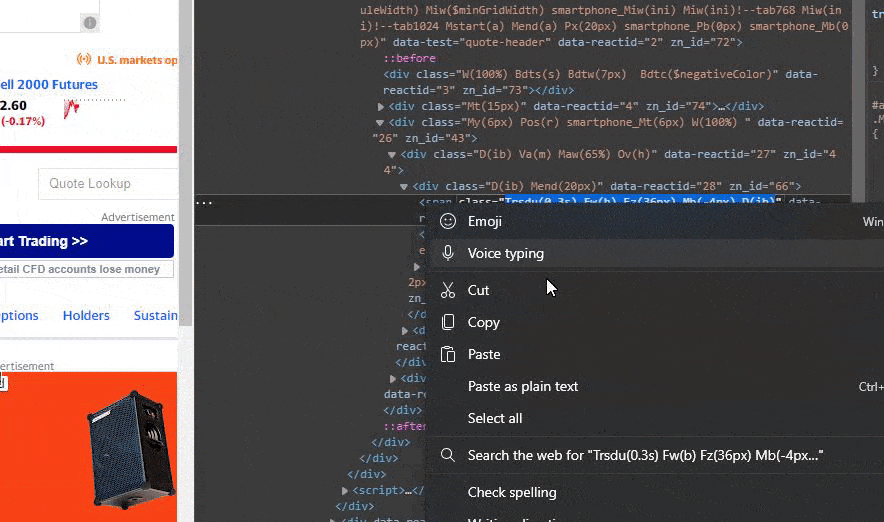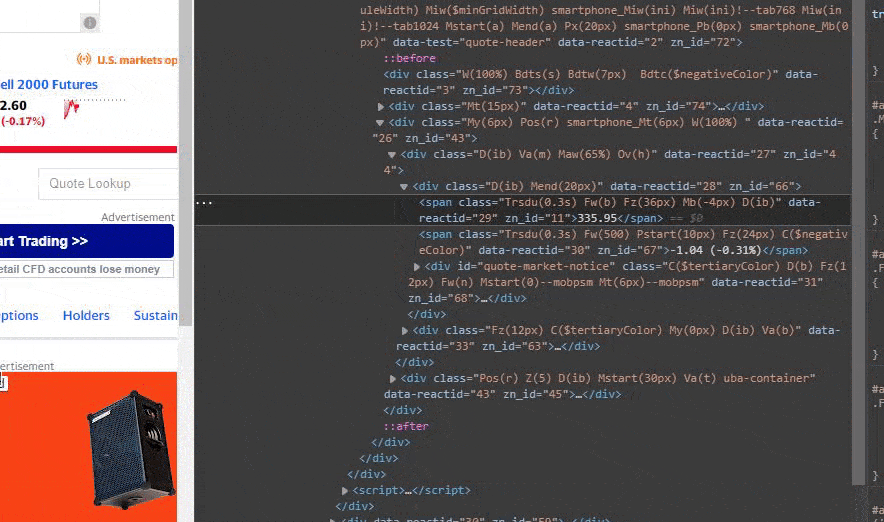
So far so good. Now we have the class property in our clipboard for the element at Yahoo Finance. this makes it possible for us to find the content of the element using soup.
Add a try-except “block” in your stockPrice.py file and add these three lines inside the try block.
soup = BeautifulSoup(stockResponse.text, 'html.parser')
price = soup.find('body').find(class_='Trsdu(0.3s) Fw(b) Fz(36px) Mb(-4px) D(ib)')
print('The latest stock price for ' + ticker + ' is: ' + price.text.strip())What happens above?
- The first line will parse the response data from our get request to Yahoo Finance.
- The second line will find the stock price by using the element value we provided from the DOM of the webpage.
- The third line will print the content of the price variable using
price.text.stripmethod.
Inside the except block, add this print: print('Invalid ticker, please try again.'). You should now have a stockPrice.py file like this:
import os
import sys
import requests
from bs4 import BeautifulSoup
if len(sys.argv) > 2:
print('You are only allowed to enter one ticker at a time. Please try again.')
sys.exit()
if len(sys.argv) < 2:
print('You have to provide a ticker for the stock. Please try again.')
sys.exit()
ticker = sys.argv[1]
stockURL = 'https://finance.yahoo.com/quote/' + ticker + '?p=' + ticker + '&.tsrc=fin-srch'
stockResponse = requests.get(stockURL)
try:
soup = BeautifulSoup(stockResponse.text, 'html.parser')
price = soup.find('body').find(class_='Trsdu(0.3s) Fw(b) Fz(36px) Mb(-4px) D(ib)')
print('The latest stock price for ' + ticker + ' is: ' + price.text.strip())
except:
print('Invalid ticker, please try again.')Test the Python Stock Web Scraper
Below is the result of different types of tests made for the stock price scraper.
Check Microsoft Stock Price
PS C:\Users\chs\Desktop> python .\stockPrice.py MSFT
The latest stock price for MSFT is: 335.68Error testing
Let’s see if our error handling code will inform the users if they make any mistakes.
Too many tickers
PS C:\Users\chs\Desktop> python .\stockPrice.py MSFT AAPL
You are only allowed to enter one ticker at a time. Please try again.No tickers
PS C:\Users\chs\Desktop> python .\stockPrice.py
You have to provide a ticker for the stock. Please try again.Invalid ticker
PS C:\Users\chs\Desktop> python .\stockPrice.py CHRISTIAN
Invalid ticker, please try again.Summary
You have now learned how to scrape data from a webpage by using elements, dynamic arguments, and displaying the data inside a command-line interface. How cool is that?
I hope this short tutorial has helped you gain some knowledge about how easy it is to use python beautiful soup to scrape the internet for data. If you got any questions or suggestions, please let me know in the comments. Happy coding! 🙂